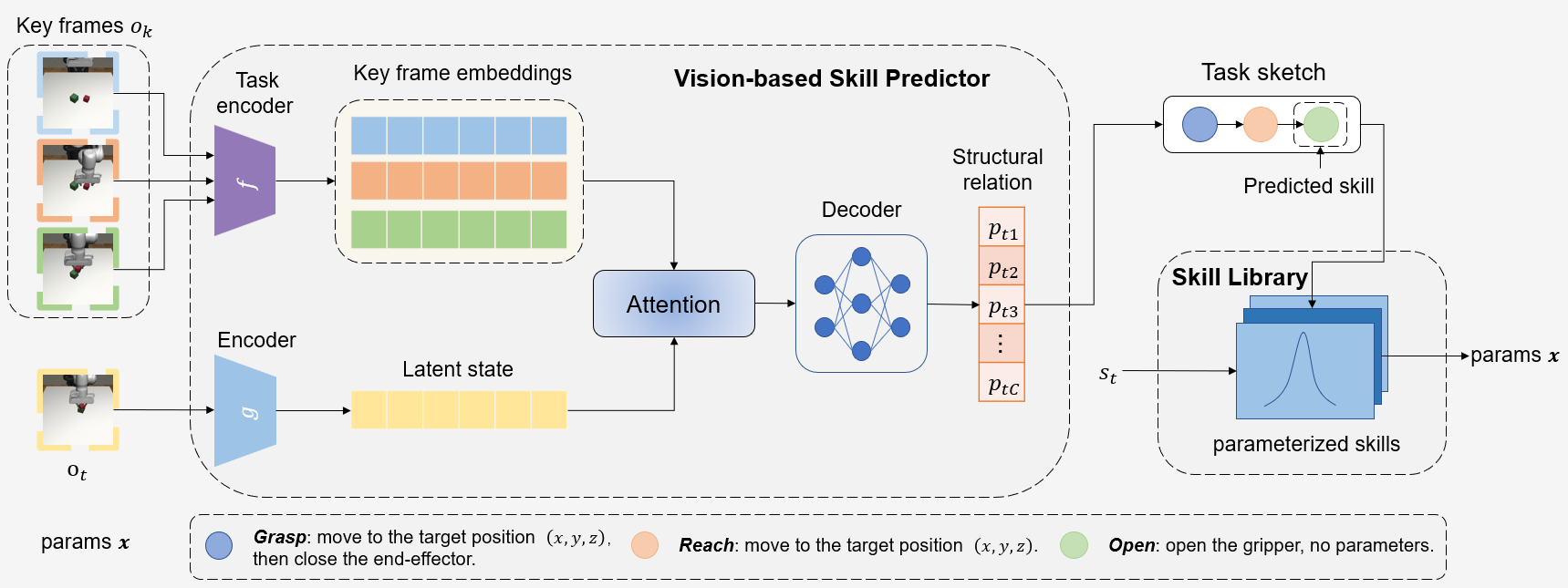
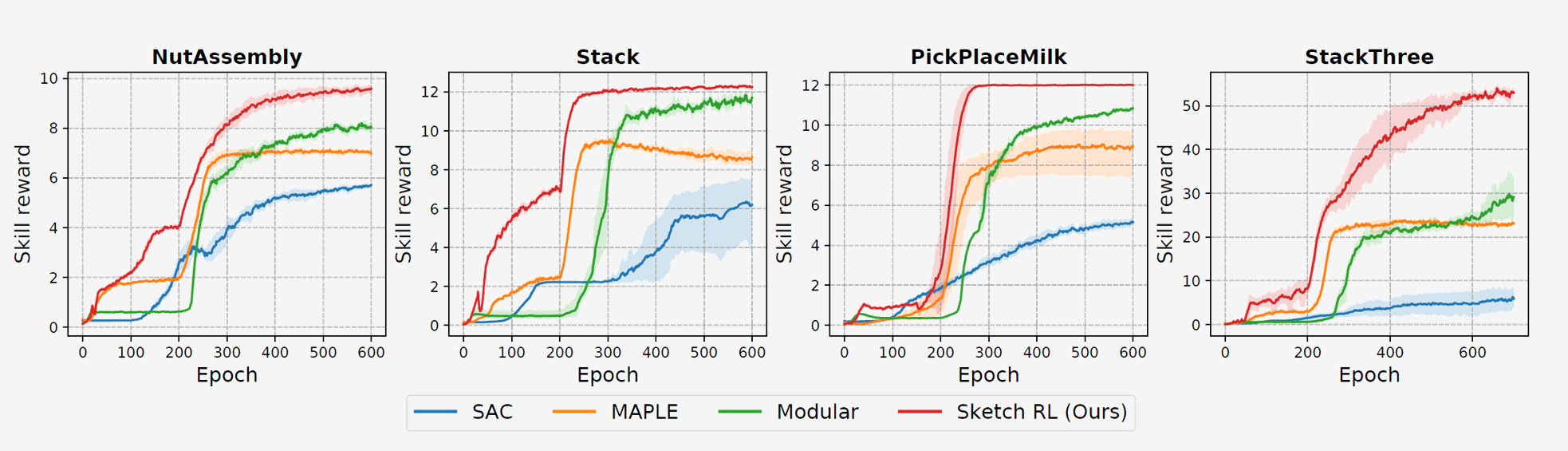
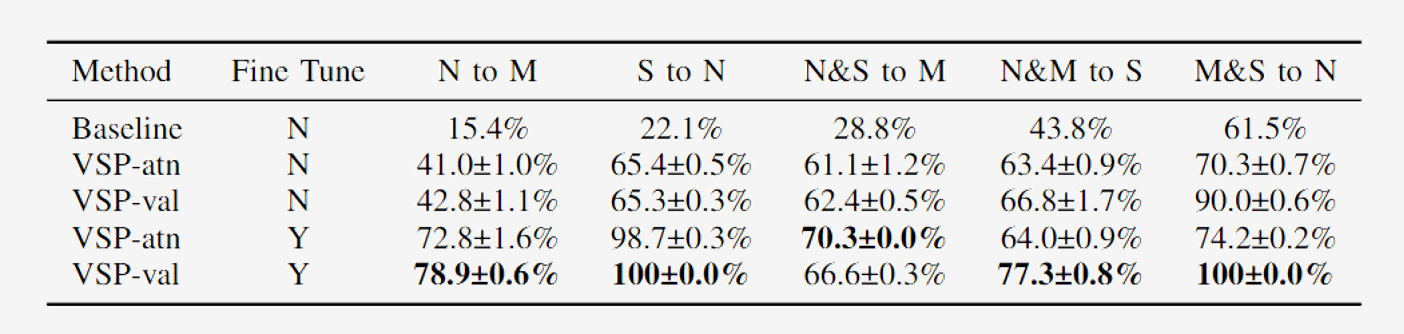
Sketch RL Overview
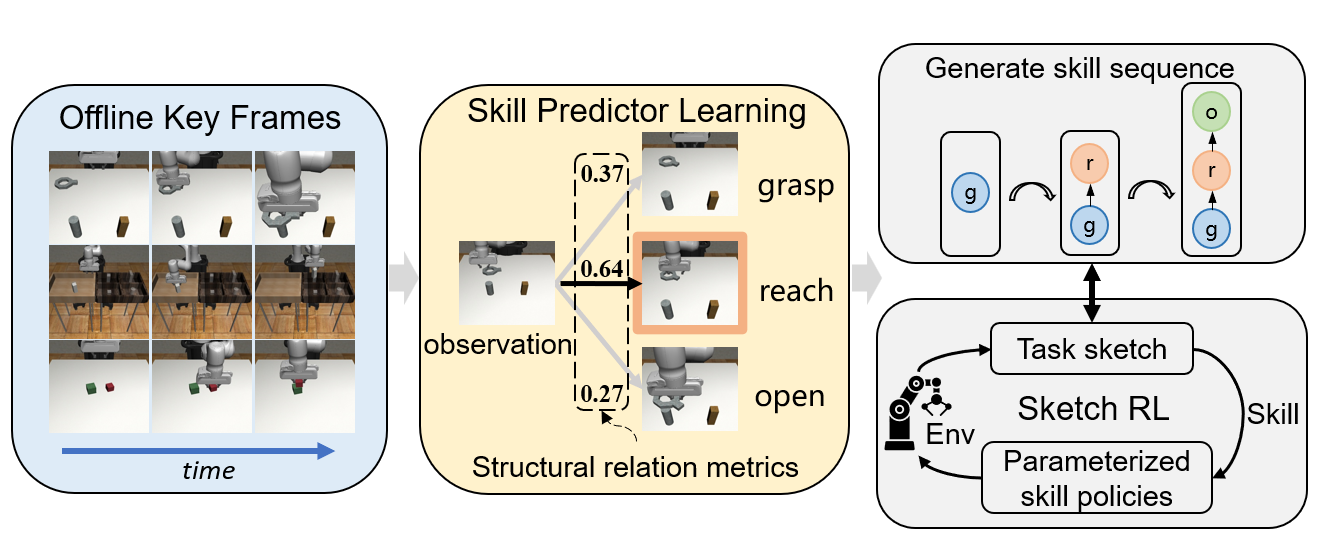
we develop Sketch RL, an interactive hierarchical policy learning system that embeds skill transition dynamics of tasks into the process of low-level skill learning, which enables improvement in exploration efficiency for complex manipulation tasks and generalization to new tasks unseen during training. The first phase is to train the Vision-based Skill Predictor (VSP) module to predict the next primitive skill with visual inputs by comparing the structural similarity between the current frame and different key frames of a task. By capturing the shared subtask structure, this paradigm of supervised learning based on visual inputs can in principle enable the high-level task planner to deal with multitask decomposition and generalization few- shot to new tasks.